Maybe you misunderstood the author. They wrote: ‘It’s not that I think menu items should never have icons. I think they can be incredibly useful. It’s more that I don’t like the idea of “give each menu item an icon” being the default approach.’
The point is, if every item in a long menu has an icon, then they typically can’t all be very distinguishable and recognizable, and blur together visually. It creates more visual noise, and less structure, than if only some items had an icon.
As for finding groups quickly, for example it doesn’t make sense give all of “Save”, “Save as…”, “Save all” an icon, but giving the first one an icon helps to recognize the “Save” group of operations.
Aren't the icons for the different save actions typically different? The save as typically has some idea of editing, like a pencil or an editing box, save all has multiple save icons behind each other.
But isn’t the second half of the article the author pointing out a bunch of menu examples from macOS Tahoe where some items have icons and others don’t and still coming to the conclusion that it’s confusing? How is that not a contradiction of the prior declaration?
Yeah, that's a bit inconsistent. I think they are criticizing that it appears to be random which menu items have icons assigned, instead of (for example) giving all important or frequently used items an icon, or in some way that creates visual structure in the menu. Personally, what I find the most disconcerting in those examples is that the menu items aren't consistently inset.
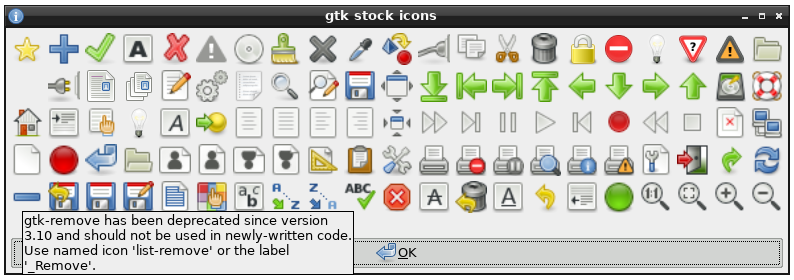
Here is what I would think is a fairly good use of icons: https://learn.microsoft.com/en-us/windows/win32/uxguide/imag...
The icons are positioned such that they introduce groups of menu items, and they create a visual structure that one learns to recognize with repeated use.
I'm gonna guess just switching from round-robin to leastconn (most balancers offer that option) would solve that just fine. You can then go to dynamically tune server weights if you have servers of unequal size or some other issues.
Yeah I really don't understand why they went this direction as it builds considerable additional complexity directly into the application to solve a problem with an external component
I would have probably approached this by implementing a fix for the misbehaving part of k8s, though since there isnt a default LoadBalancer in k8s, I can't really can't speculate further as to the root cause of the initial problem. But most CNI or cloud providers that implement LB do have a way to take feedback from an external metric. I'd be curious why doing it this way wasn't considered, at least.
Yeah, that can work. Just yesterday I benchmarked load balancing of LLM workloads across 2 GPUs using a simple least_conn from nginx. The total token/sec scaled as expected (2 GPUs => 2x token/sec), and GPU utilization reached 100% on both, as I increased concurrency from 1 to 128 simultaneous generations.
Because AI, or rather, an LLM, is the consensus of many human experts as encoded in its embedding. So it is better, but only for those who are already expert in what they're asking.
The problem is, you have to know enough about the subject on which you're asking a question to land in the right place in the embedding. If you don't, you'll just get bunk. (I know it's popular to call AI bunk "hallucinations" these days, but really if it was being spouted by a half wit human we'd just call it "bunk".)
So you really have to be an expert in order to maximize your use of an LLM. And even then, you'll only be able to maximize your use of that LLM in the field in which your expertise lies.
A programmer, for instance, will likely never be able to ask a coherent enough question about economics or oncology for an LLM to give a reliable answer. Similarly, an oncologist will never be able to give a coherent enough software specification for an LLM to write an application for him or her.
That's the achilles heel of AI today as implemented by LLMs.
> The problem is, you have to know enough about the subject on which you're asking a question to land in the right place in the embedding
The other day i was on a call with 3 or 4 other people solving a config problem in a specific system. One of them asked chatgpt for the solution and got back a list of configuration steps to follow. He started the steps but one of them mentioned configuring an option that did not exist in the system at all. Textbook hallucination. It was obvious on the call that he was very surprised that the AI would give him an incorrect result, he was 100% convinced the answer was what the LLM said and never once thought to question what the LLM returned.
I've had a couple of instances with friends being equally shocked when an LLM turned out to be wrong. One of which was fairly disturbing, I was at a horse track and describing LLMs and to demonstrate i took a picture of the racing form thing and asked the LLM to formulate a medium risk betting strategy. My friend immediatately took it as some kind of supernatural insight and bet $100 on the plan it came up with. It was as if he believed the LLM could tell the future.Thank god it didn't work and he lost about $70. Had he won I don't know what would have happened, he probably would have asked again and bet everything he had.
Yup, current LLMs are trained on the best and the worst we can offer. I think there's value in training smaller models with strictly curated datasets, to guarantee they've learned from trustworthy sources.
> to guarantee they've learned from trustworthy sources.
i don't see how this will every work. Even in hard science there's debate over what content is trustworthy and what is not. Imagine trying to declare your source of training material on religion, philosophy, or politics "trustworthy".
"Sir, I want an LLM to design architecture, not to debate philosophy."
But really, you leave the curation to real humans, institutions with ethical procedures already in place. I don't want Goole or Elon dictating what truth is, but I wouldn't mind if NASA or other aerospace institutions dictated what is truth in that space.
Of course, the dataset should have a list of every document/source used, so others can audit it. I know, unthinkable in this corporate world, but one can dream.
Not really, kerosene is pretty close to heavy fuel oil on density.
Planes run on kerosene because it's universal enough, hard to run them on heavy fuel, and there is issue with high emission of the HFO over population centers which isn't as much of a problem in middle of sea
They spend like a day at port so there is a bit of time to load. The logistics of getting the power to the port gonna be harder, as it's literally hundreds of megawatts to load it at reasonable rate
Freedom to walk anywhere means someone can walk onto your property ("done to you") You can curtail that freedom, because you are essentially giving up ("inability to do something with stuff someone else owns") some freedom to get some other freedom ("ability to own stuff that will not be used by strangers").
It's a tradeoff. A good one. Tradeoff of say "nobody's anything is private now because that allows govt a slightly easier time to catch criminals" is not a good tradeoff.
{kind=link}
{kind=link}
reply