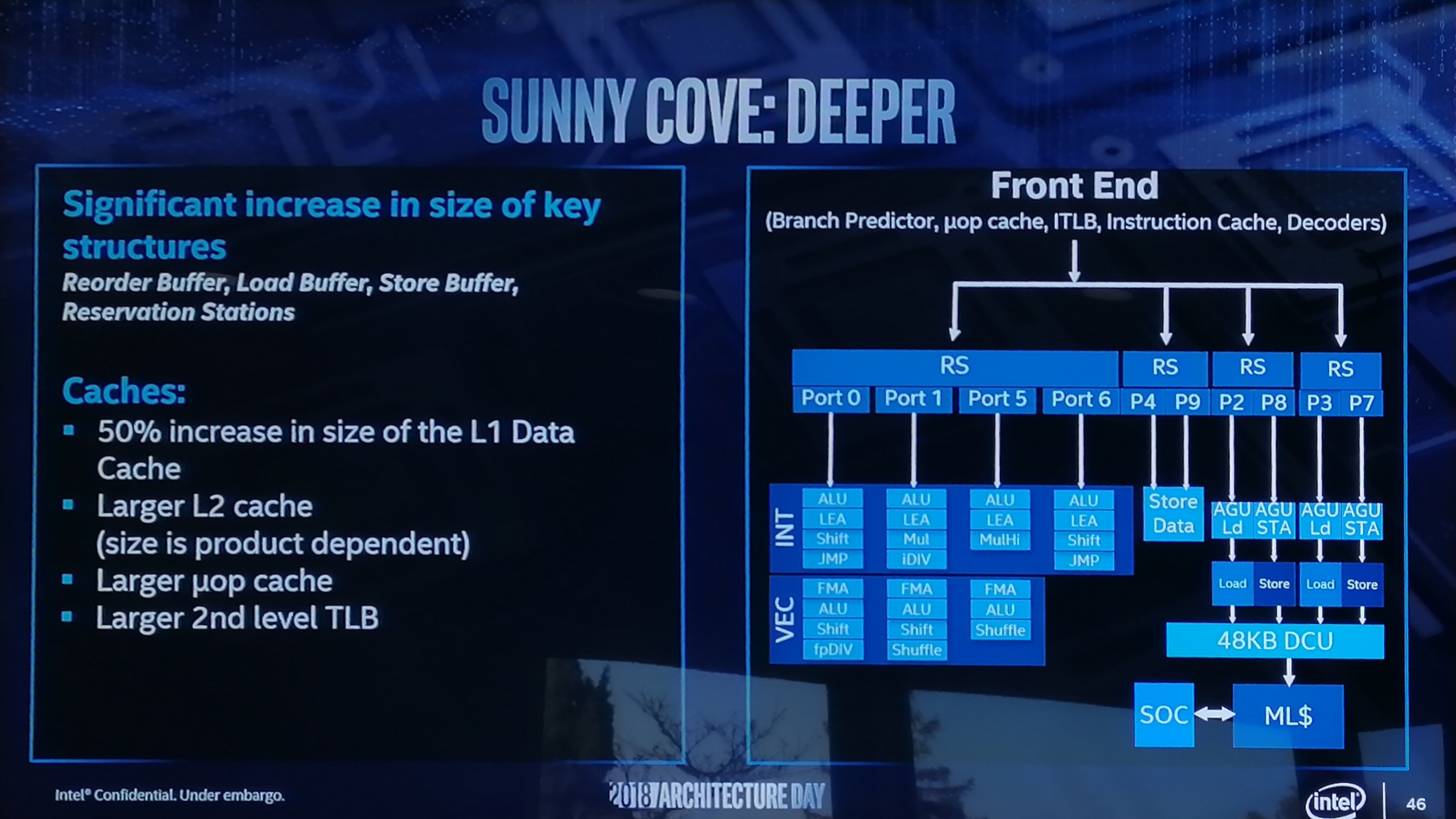
The performance of software is influenced by the workings of tens of units (+local caches) connected (non-linearly) with fifos, ooo buffers, replay mechanism.
There are multiple versions of the same unit to save chip space (like light and heavy Integer/FP).
Units/domains have different clock speeds.
And from generation to generation port connections and instructions between pipelines can be reshuffled.
I suppose what keeps performance changes relatively straightforward for developers is the set of benchmarks used to evaluate the hardware early on.
I appreciate the article focusing on the I-Cache, and the nice intro to decoding.
I would have preferred having an example, and improving something instead of abstractly talking about problems, effects of code and optimizations and possible workarounds.
Tangent: I wonder if we will be seeing specialized instructions sometime that span multiple units and multiple cores in order to reduce data-movement. Think matrix-matrix multiplication. The potential improvements for power and speed seem huge.
This is, in a nutshell, why high-performance systems engineering is a rare skill set. It entails writing C++ (or whatever) with full understanding of the machine code that is likely to generate and how that machine code will interact with the incredibly complex internals of modern microarchitectures. It essentially requires de-abstracting two levels of abstraction below the programming language, which exist to reduce cognitive load, in your software design and implementation.
It is unfortunate that this is still so useful in practice, given what it implies about the magnitude of waste in typical software systems.
That skill set is helpful, but you can go a long way with profiling tools to find what's your bottleneck is spending the most time on, and try to do less of that. And, in general, trying to work with the least amount of abstraction amd making sure the abstractions you use match the underlying reality as much as possible. Almost always, you can't add a layer to get performance, just like you can't usually add a layer to get code quality, and you can't usually add a layer to get security.
Obviously, abstractions are useful, but it can be very hard to dig out of wrong abstractions, when they've influenced the design of the whole project.
What's interesting is that with the death of Moore's Law there's a sudden increased interest in accelerators (software or hardware assisted), specialized pieces of software/hardware that can perform certain tasks really fast and then integrating these in a PC system to boost performance of certain common tasks. Thus I found myself having to spend a lot more time lately learning how cache affects the code I write, branch prediction, speculative execution, etc. It feels like starting out learning to program all over again.
One of the criticisms of the C++ standardization efforts is how many of the improvements are quitearcane. But those arcane features aren't necessarily for user code but to make library code efficient. Implementations of the standard library are often almost unreadable because of all the weird corner cases and performance optimizations they have to transparently handle.
This can go a long way to improving user code...but of course it's no magic bullet.
I really dislike this mindset in the C++ community. The people writing libraries are normal programmers too. They're not some kind of supermen on whom you can load infinite complexity. And it's not like the STL is this amazing piece of software that mere mortals can't beat. Quite the contrary, any sufficiently large piece of software tends to replace the STL at least in parts with their own implementation.
Herb Stutter mentioned once that an advantage of the STL is that it gets you good general-purpose performance initially, but tries to stay out of your way if you want to replace it for something more specialized.
I think you’re right about a codebase replacing parts of STL as necessary. One I see frequently is `std::array` being wrapped with iterators to be essentially a stack-allocated vector.
Practice is a main ingredient. Build and debug (down to below assembler level with i.e. vtunes, learn about weak memory ordering, ...) increasingly complex systems.
Learn how high level language code is transformed into "what the hardware shall do" to be able to predict, to some degree, whether that particular code you review will be optimized well or not (then measure and confirm/extend/correct your prediction).
Working with FPGAs helped me learning a lot about how to get the right data to the right execution unit at the right point in time. Solving this "space-time-problem" is exactly what optimizing is about in CPUs as well.
For the engineering part I'd say: being strict about separation of concerns and single source principles and not too religious with abstractions certainly helps.
And finally: read, read, read. Books, Papers, other people's code...
Oh, and one more thing (tm): try to be the worst, not the best team member. Make sure you always can learn from peers. You need discussions, especially those wandering up and down the abstraction stack, asking "why" on every level.
> There are multiple versions of the same unit to save chip space (like light and heavy Integer/FP).
I've literally never heard of this. I know you can have multiple execution units for parallel instruction execution, but 'light' and 'heavy' - can you give some info or a link? TIA
I believe this shows differences between FP and Integer units.
In order to achieve a certain performance goal you don't necessarily need another integer divider when you want a new adder/multiplier. So you add a slimmer unit instead.
I listed this in my original comment, because this is a giant can of worms for the compiler and decision-maker on where to execute what.
Ah, thanks. The slide is interesting for extra reasons.
With respect, I think you're misunderstanding. I thought you meant light/heavy versions of eg. adders, for some definition of light and heavy addition.
I'm not an expert but... CPUs will put in extra execution units according to need (will typical code get faster with an extra X?) and cost.
Shifters are typically very often used, and are simple. So are adders, though more complex. IIRC recent intel x64 will have several of of each[0]. Multipliers are less cheap so they have fewer (and often you can turn them into adds in certain cases such as progressive array lookups). Division is slow and very expensive in transistors, so they have 1 (division can often be turned into reciprocal multiplication anyway). Sqrt is even worse.
And to repeat, I'm no expert and any corrections welcome.
Do ports (as in the picture) have independent pipelines, or do they execute certain pipeline stages of a big pipeline?
I suppose, either way you can't issue to the same port in the same cycle.
This paper sheds some light on how instructions are divied up between units on NVIDIA GPUs.
http://www.stuffedcow.net/files/gpuarch-ispass2010.pdf
Table IV.
Notice that fp32 mul is in the SFU and SP, while others are not.
I'm the wrong guy to answer this but I believe the ports are available to one pipeline, so no independent pipelines, but instructions behind the 'head' can hop over the head if the head is stalled, if there are execution units free. Instructions can get reordered, over quite a wide window, something like 200 instructions (look up the reorder buffer, ROB, although there's another windows which affects this, something to do with retiring instructions).
Yep, but also while aligned. Bits x and y are going to be the same distance apart, always, unless shifted off the end (where they can wrap or be lost). Thinking of this in the pub it seemed a butterfly thingy would be appropriate <https://en.wikipedia.org/wiki/Butterfly_network>.
Further thinking suggested there'd be a ton of wires doing this, and perhaps it's the wiring that's taking up the silicon?
I've been wondering about the impact of insturction cache misses and potential downsides of executable bloat caused by C++ templates, but have never seen a real case of this being a problem.
In 2010 Endeca's analytics engine exe was growing substantially via introduction of template instantiations. The engine eventually crossed the threshold of instruction cache misses outweighing the benefits of avoiding type lookups at runtime, and the team agreed to stop pursuing template instantiation so aggressively as a performance enhancement.
I wonder if modern compilers would have allowed the team to keep at it.
It's been a while, but if I recall correctly, the optimized, stripped exe's at the time were a bit under 100mb. >500mb with debug symbols, etc.
Executable bloat can be avoided by stripping the executable afterwards, if that's what you mean: Although the function body will have been provided if instantiated and used, the compiler will have probably inlined a huge amount of any code that is actually used - a lot of templated stuff is made up of one liners or single uses, which compilers are very very good about reasoning through the motion of these days.
I guess a naive compiler could have issues but every time I check something on compiler explorer, the modern big boys (GCC, LLVM, ICC?) are pretty shrewd (Especially if you optimise for size).
While aggressive inlining eliminates function call overhead, it can actually exacerbate instruction cache misses because it makes the executable larger.
I don't understand where does this sentiment come from. I've once seen a complete high-level networking algorithm implemented with boost.asio be reduced to less than 250 instructions...
Modern C++ compilers are pretty good at minimizing template bloat. As with most things in C++ it requires some awareness and intent to optimize this but it isn't the issue it used to be in many cases.
perf-tools are my favorite. The overhead is negligible, and thus any metrics you gather are very accurate. Valgrind is rarely useful, considering the execution time disadvantage.
Another big issue is iTLB misses. Today if you profile a real-life application, the iTLB miss rates can be 5%+ due to increased program image size. Splitting hot/cold variant like this article also works for this problem, but I was wondering if we can use transparent huge page on code while disabling it for mmapped data pages
{kind=link}
The performance of software is influenced by the workings of tens of units (+local caches) connected (non-linearly) with fifos, ooo buffers, replay mechanism. There are multiple versions of the same unit to save chip space (like light and heavy Integer/FP). Units/domains have different clock speeds. And from generation to generation port connections and instructions between pipelines can be reshuffled.
I suppose what keeps performance changes relatively straightforward for developers is the set of benchmarks used to evaluate the hardware early on.
I appreciate the article focusing on the I-Cache, and the nice intro to decoding.
I would have preferred having an example, and improving something instead of abstractly talking about problems, effects of code and optimizations and possible workarounds.
Tangent: I wonder if we will be seeing specialized instructions sometime that span multiple units and multiple cores in order to reduce data-movement. Think matrix-matrix multiplication. The potential improvements for power and speed seem huge.