Running a site the size of the BBC on Lambda is nothing short of an exuberant waste of a government-subsidized budget, it's absolutely crazy.
Lambda VM time has a massive markup compared to regular compute. It only makes sense where usage does not exceed some threshold the BBC absolutely certainly do.
There are plenty of alternative options, even on AWS, that don't suffer from such huge markup without requiring any additional ops input. The thing that runs in Lambda is practically a container image already. Does it really cost tangible budget to have CI build a full image rather than a ZIP file that already contains a few million lines of third party JS/Python deps?
IMHO this is the epitome of serverless gone wrong.
AWS Lambda
$0.20 per 1M requests
$0.0000166667 for every GB-second
SLA 99.95%
Lets assume
- 2000 calls/sec
- each call is 1 sec duration
- 0.128 GB/sec/call
- db, storage iops will be the same if deployed as K8s
- 5x9s SLA (imples a three region deployment)
The equivalent K8s would be
- three clusters
- 2000 cores (more likely 10% more = 2200)
- 256GB memory
Three clusters will require 3000 cores to cater for region loss
- 3000 cores on 32 core machines => 94 machines
- round up to 99 machines to give vm level redundancy
=> 33 machines per cluster
I responded lower, but dude! 2000 requests a second is hardly anything at all, unless the application server is doing some seriously heavy lifting in which case the architecture is wrong.
You should redo the calculations with 1gb of memory for Lambda and like 30 machines would be generous
Concurrency is key. Requests don't cost much when they're just waiting for other things, but Lambda continues to pile costs on for every increase in concurrency.
APIs should maybe use a tiny fraction actual real CPU time. Perhaps BBCs are different - In order to make an actual fair comparison and properly predict what they would need in servers, greater detail is needed than what you have available to you, but I think your estimations are off by a significant amount.
I stopped reading at "3000 cores"; there is a lot of money to be made mopping up disasters like that, it's clearly even something of a growth industry. We had one machine push 2,400 requests/sec average over election night, without even touching 30% capacity, costing around $600/mo including bandwidth. Its mirror in another region costs slightly more at $800/mo. As a side note, it's always the case with those folk that they invent new employees to top up their estimates, that wouldn't be required in the serverless world, yet in every serverless project I've ever seen, they absolutely still existed because they had to.
Price-perf ratio between Lambda and EC2 is obscene, even before accounting for Lambda's 100ms billing granularity, per-request fees, provisioned capacity or API Gateway. Assuming one request to a 1 vCPU, 1,792MB worker that lasted all month (impossible, I know), this comes to around $76, compared to (for example) a 1.7GB 1 vCPU m1.small at $32/mo or $17.50/mo partial upfront reserved.
Let's say we have a "50% partial-reserved" autoscaling group that never scales down, this gives us a $24.75/mo blended equivalent VM cost for a single $76 Lambda worker, or around 3x markup, rising to 6x if the ASG did scale down to 50% its size the entire month. That's totally fine if you're running an idle Lambda load where no billing occurs, but we're talking about the BBC, one of the largest sites in the world...
The BBC actually publish some stats for 2020, their peak month was 1.5e9 page views. Counting just the News home page, this translates to what looks like 4 dynamic requests, or 2,280 requests/sec.
Assuming those 4 dynamic requests took 250ms each and were pegging 100% VM CPU, that still only works out to 570 VMs, or $14,107/mo. Let's assume the app is not insane, and on average we expect 30 requests/sec per VM (probably switching out the m1.medium for a larger size taking proportionally increased load), now we're looking at something much more representative of a typical app deployment on EC2, $1,881/mo. on VM time. Multiply by 1.5x to account for a 100% idle backup ASG in another region and we have a final sane figure: $2,821/mo.
As an aside, I don't know anyone using 128mb workers for anything interactive not because of memory requirements, but because CPU timeslice scales with memory. For almost every load I've worked with, we ended up using 1,536mb slices as a good latency/cost tradeoff.
Just for completeness, updating parent comment's Lambda estimates, not counting provisioned worker costs, and assuming no request takes more than 100 ms.
Note the "1 req/vCPU" case would require requests to burn 250ms of pure CPU (i.e. not sleeping on IO) each -- which in an equivalent scenario would inflate the Lambda CPU usage by 3x due to the 100ms billing granularity, i.e. an extra $30,000/month.
That's an 87% reduction in operational costs in the ideal (and not uncommon!) case, and a minimum of a 59% reduction in the case of a web app from hell burning 250 ms CPU per request.
Totally agree. Lambda needs to 1/10 their costs or start billing for real CPU time and get rid of invocation overheads to really compete at these scales.
Now I have dozens of serverless projects for smaller use things because there is still a point where the gross costs just don't matter (as in, if my employer was worried about lambda vs EC2 efficiency, there are probably a few meetings we could cancel or trim the audience of that would make up for it.)
Lambda has huge potential for very defined work load. In this case, I do not get it. As you mentioned the idea of having 3 regions with 3000 cores? Are you doing ML on K8s? Another aspect is the caching with CDN and internally, I do not get that either.
What you are missing are the Amazon API Gateway costs. I really liked my own calculations on Lambda costs similar to yours until I figured I'd need to use API Gateway too.
Edit: another thing is the amount of RAM used by functions. The CPU speed you get is proportional to RAM so if your code fits in the RAM but has poor performance, doubling the RAM is what you have to do. Another hidden cost.
The calculations are still a little more complicated. I think serverless is the future, but I also think we need to continue to put pressure on AWS to lower costs
Lambda and servers are not equal, you can't just calculate the number of servers one would need for an equivalent Lambda load. It's entirely possible that they could get away with significantly fewer servers than you think.
Your cost calculation includes 128mb provisioned. You cannot run an API with 128mb Lambdas. Try 1gb or even 1.5gb. It's not that you need that much memory of course, but if you want to have p98 execution and initialization times that are palatable, you need the proportional speed benefits that come with the additional memory.
And no, you won't need API gateway because you'd likely be including your own in your cluster and it will handle far more load without needing nearly as much autoscaling as the app servers.
Lambda autoscales too - it's not instant, and there are steps it goes through as it ramps up.
If Lambda removed the per-invocation overhead and billed for actual CPU time used, not "executing" (wall) time, I think that would be fantastic. Again, I still think it's the future, but it has a ways to go before it's appropriate for certain use cases and load profiles.
Edit: oh, and I think the managed ROI is also a case by case basis. Do you have people who know how to run a cluster for you already? Completely different conversation.
I will also say that Lambda is still not maintenance-free, either.
How does one invoke a Lambda function via HTTP without an AWS account (ie a public API call)? I think you are not including it in the "most workloads"?
Most if not all AWS services are really just HTTP APIs. A Lambda invocation is really just a POST to a public AWS endpoint. You can absolutely come up with login flows that obtain a set of temporary STS credentials that are only allowed to invoke your "API" function. (Agreed this is not most workloads)
Completely agree. What also irks me is the corpspeak sleigh of hand, where the problem of maintaining your infrastructure is “solved” by using AWS Lambda. It’s not solved, you’re just paying some AWS contractors to do it for you and you assume it’ll be alright.
> It’s not solved, you’re just paying some AWS contractors to do it for you and you assume it’ll be alright.
In as much as maintaining infrastructure can ever be 'solved', doesn't paying someone else who does a good job of it to provide you with the infra count as solving the problem? Otherwise you'd be down the mines picking ore out of the ground so you can build your chips right, rather than relying on intel/AMD to do it for you and assuming it'll be alright.
The problem arises when the infra providers’ setup stops being aligned with yours. Which, given a small organization and a long enough period of time, is guaranteed to happen.
The question is then: is it just cheaper in the long run to deal with the hassle of your own infra (we are still talking about the cloud, btw, the thing that supposedly already solved it) or would it be ok to follow the practices and changes in the providers offering?
I run the News Sniffer[1] project which has to parse BBC News pages and I knew about this rollout a few weeks ago when the HTML all changed format completely and my parsers broke.
As a side note, the new HTML is way more complicated and much harder to parse than before - I know the aim isn't to help parsing for content, but I was still saddened to see how it's ended up (a bit of a mess imo - hard to distinguish actual article content from other things).
If anyone knows a reliable and public way to access the content before the "web rendering" layer, that'd be very handy!
The BBC was huge on semantic web and rdf a few years ago. When you start using React and using the tools and techniques common with React or even just composing your site follow today’s common methods the semantic web is extremely difficult, especially with elements being created at runtime in the browser adhoc.
It’s kind of where we started in the early 2000s and gone full circle. CSS was created to remove the intended style of the site being crafted by the structure of the content. We now have CSS frameworks that dictate how you define the content for layout to take effect.
If they have a mobile app, often looking at the requests that it makes can be enlightening, and the same story if the have a mobile version of the site, as it tends to have less "fluff" and more content
I also know they have a moderately public Nitro API for their media programming (the iPlayer offerings) so it's possible they have a similar one for their web content
nice thanks, that looked promising but I've checked a number of older articles and they have no amp version (despite the HTML for the site referencing an amp version, the url is 404!)
I'll see if I can figure out if all newer pages will have permanent amp versions, or whether all amp versions drop away over time.
Maybe my side project rss-proxy [0] might be interesting for you. It analyzes the dom and extracts the articles, so ideally you would not need to write a parser manually.
yes, though the page linking to them hasn't been updated since 2011. And notably, it doesn't have the new HTML: https://www.bbc.co.uk/news/10628494
But the RSS feeds are just the headlines. And also don't contain every article ever - only the latest ones with a limit. So not much use to News Sniffer.
I notice that the previous post from the same author, dated 2017, was titled "Powering BBC Online with nanoservices" [0]. Nary a mention of nanoservices now. If I were a cynic, I would say they are going out of fashion.
The BBC seems extremely good at building large, complex websites. They appear to have acheived this ability by chooosing to continuously build new large, complex websites. Obviously as an organisation the BBC isn't actually doing many new things and as a result the BBC's engineering department has been forced into an awkward position where they're continuously building the same new large complex website. It's stunning that the first part of this article wasn't what they wanted to actually acheive by writing a new website beyond the obviously false "For them all, we need to ensure they use the latest and best technology. That’s the only way to ensure they’re the best at what they do."
Frankly I giggled a little with the image showing a spot the difference. Well done, you spent tens of millions and the website looks identical.
This is the natural result of building a publicly funded empire of literally hundreds of ex-perl hackers in a room and telling them (i) justify your job and (ii) you are not allowed to do anything different because the BBC must not compete with private sector websites. Looking forward to the next iteration in raku using My::Cro.
> The BBC’s site is made up of several services (such as iPlayer, Sounds, News and Sport). For them all, we need to ensure they use the latest and best technology. That’s the only way to ensure they’re the best at what they do.
"We need to use new shiny because new shiny is the best!"
They've always been like that. I had the misfortune of having to integrate with some of their stuff they'd thrown on to ruby on rails back when it was teetering on the top of hype mountain.
Realistically 99% of their back end at the time was bits of sticky tape, perl and ftp. They just changed those components out for modern versions of sticky tape, perl and ftp...
I mean at least it's honest. If you can't afford to pay well you can probably attract better-than-you-can-afford talent by giving them creative freedom and letting them resume build a bit.
Previously they mostly used a typical lamp stack in the front end. The php apps pulled data from Java backend services. They had a strict separation policy.
The different parts of the bbc where essentially different apps with a proxy in front doing path based routing.
You’d generate a RPM with your php app / Java app and that got deployed.
That had a few drawbacks mostly around process, it was a pain to get releases out as had to go through a single team who could deploy your rpm. You also had the inflexibility of a fixed sized pool of servers in a dc you manage.
When they first started using cloud that mostly remained the same but streamlined process. You provide a rpm using the current lamp/Java stack, a build process baked that in to an ami you could deploy. That made deployments more flexible in you was not constrained by the current physical hardware available and removed the dependency having a specific team do the deployment manually on a shared host.
I imagine the hosting started to get expensive with the dedicated hosts per service. Im guessing slowly the more they used aws services and trialing things they ended up where they are which sounds super complex.
I’m not familiar with where they are now other than the article but I’d bet going back to an app such as php, Java, ruby whatever on the fronted and binpacking them with kubernetes would be simpler than dealing with thousands of lambdas on a black box runtime. Most of the stuff at the bbc hits the edge proxies/cache anyway so the remotes are fairly idle.
The BBC is facing a massive cash crunch right now they need to do everything they can to save cash right now I suspect this isn't a long term strategy so much as an act of desperation.
I'm not from the UK, but from reading the warning I used to get when watching Doctor Who over a VPN on iPlayer, you still have to have a TV License even if you only use iPlayer. How they would detect that I'm not sure (maybe the van can sniff https traffic /s), but is there a streaming service that has the BBC's content without the license?
>you still have to have a TV License even if you only use iPlayer.
Yes, that's correct - they changed the law a few years ago (previously it only applied to Live TV, using iPlayer was exempt from a TV License)
>How they would detect that I'm not sure (maybe the van can sniff https traffic /s)
I don't think they do anything with it yet, but when they do I'm pretty sure they'll take their log data of IPs accessing programme content from their CDN and ask the corresponding UK ISPs to identify if any of those accesses were from people at (list of addresses without a license) and issue a warning, and then request their details to bring them to court if they keep using it. I'm sure the ISPs will be willing to help them, and even as a privacy advocate I can't say I'd be bothered by this - those people are using a service they have not paid for.
It does seem like it'd be easier to simply require that you pay for your TV License through your BBC account, though, since that blocks anybody on a VPN who doesn't hold a license.
>but is there a streaming service that has the BBC's content without the license?
BBC does license their content worldwide, and there's a strange relationship with BBC America - so if you're wanting to access it legally outside the UK that's your best approach. Within the UK, Netflix certainly has a (limited, but good) number of BBC programmes licensed.
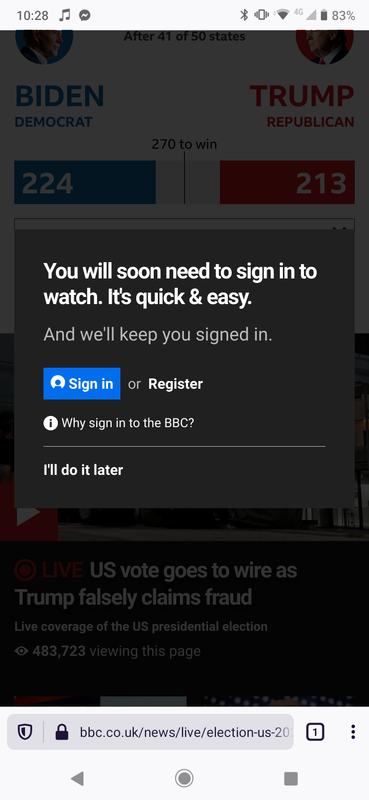
The BBC has a big problem with cargo cultery right now, copying large social media companies for the hell of it despite having completely different aims. For instance, if I tap the livestream on the homepage it will lie that I need to sign in to watch it, though the popup can just be dismissed. It's shocking that they've adopted useless metrics like conversion to justify user-hostile behaviour.
I don't think you're supposed to be able to dismiss it - it's not about conversion, you're supposed to need an account so that you've had to agree 'I have a television licence'.
Me too. The other argument, of course, is that instead of spending 10x on (taxpaying) staff and employees within the UK, in order to create a new technology that may be useful and solve other problems, they are spending 1x on Amazon. Amazon will not pay any tax within the UK, and, moreover, have motives that are arguably aligned to the detriment of the BBC.
I'm slightly sad to read about the change. In many ways, I'd rather the perl duck tape & php approach, running on real computers that the BBC owns. Maybe that officially makes me old.
> instead of spending 10x on (taxpaying) staff and employees within the UK, in order to create a new technology that may be useful and solve other problems, they are spending 1x on Amazon.
You imply that Amazon/AWS doesn't employ any staff in the UK, which is wrong.
> Amazon will not pay any tax within the UK
Amazon must certainly pay taxes in the UK, or at least the tax ends up being paid on Amazon share price increases from employees share vesting.
Agreed, there’s very little discussion of concrete benefits here just vague assertions that this is the best way to do it (except for lighthouse test results which could surely have been fixed much more cheaply by cleaning up the incredibly woolly markup).
Also: they still can’t get two parts of the same page to consistently show the same live football result. This seemed to break about 10 years ago and no one seems to care enough to fix it.
I visited https://www.bbc.com/news/world-asia-54702974 to confirm the lighthouse scores in their article, but the Performance consistently scored ~30 instead. Why is there such a large gap between what I'm seeing and what they're seeing?
I'd like to understand how the team decided to move all of the BBC services entirely to serverless infrastructure. How is serverless the best solution for a heavily used platform? What lead management down this path?
Good question, could it be the cost or at least the illusion of cost saving? I do not know but it will interesting to see how much they are saving, if they do?
{kind=link}
Lambda VM time has a massive markup compared to regular compute. It only makes sense where usage does not exceed some threshold the BBC absolutely certainly do.
There are plenty of alternative options, even on AWS, that don't suffer from such huge markup without requiring any additional ops input. The thing that runs in Lambda is practically a container image already. Does it really cost tangible budget to have CI build a full image rather than a ZIP file that already contains a few million lines of third party JS/Python deps?
IMHO this is the epitome of serverless gone wrong.