I want to encourage everyone who doesn't like the WYSIWYG input box to use `/feedback` directly from within Slack to let the folks over there know about it. I believe this is one of those occasions in which tons of user feedback is crucial to at least make that awful thing optional.
Thanks for sharing your experience with our new formatting UI. I'm sorry to hear it's been a little disruptive so far.
There isn't a way to revert to the old formatting method, I'm afraid.
We don't currently have plans to make the new formatting configurable
though we are carefully considering all our customers' feedback.
Got the same message. Let's see if "carefully considering all our customers' feedback" means "hey, lots of people are annoyed by this" or "ignoring all our customers' feedback".
>Thanks for sharing your experience with our new formatting UI. I'm sorry to hear it's been a little disruptive so far. There isn't a way to revert to the old formatting method, I'm afraid. We don't currently have plans to make the new formatting configurable though we are carefully considering all our customers' feedback.
While the little hack is surely fun, this is an underrated comment. The tuning that SONOS speakers do at setup will also not help if the speaker's own signal characteristics are taken into account for generating the system transfer function between input signal, speaker, and room. That's how SONOS, BOSE, et al. achieve a consistent sound in the first place.
So the result with different speakers will be mediocre at best and indeed far from high quality, even with a high quality speaker strapped on to it.
> (...) very hard for small projects, like the team running Homebrew, to fund their security, yet they are likely to be a target for quite high end attackers, (...)
I disagree. Homebrew’s security considerations in this case have nothing to do with their funding. There are lot of terrific services available for next to nothing for open source projects, Jenkins is one of them. It must have been a conscious decision the way HB set up their CI, unaffected by funding.
And such lapses are not an open door jyst to “high end attackers”. This was a single person with just internet access and a little knowledge about how modern OSS projects work.
When time and money is limited, new features will always win both time and money, until something goes wrong. At that point where it's gone wrong, people will step in and lament "why didn't you just do X" for a few days, before they go back to wanting more features.
The cost of good security is high - audits, slowed down development, limited data retention, higher compute costs... and the return on that investment is only ever going to be a reduction of liability.
Big company with lots of resources, small company with no resources; it doesn't matter. Security is a cost center, and will only ever get a token amount of resources until the costs of doing nothing outweigh the costs of doing something.
Yes, security is a cost. There's a bit of tragedy of the commons effect here - many of the downsides are pushed onto others. I like Doctorow's general take on socializing costs of privacy and security breaches while privatizing profit: https://locusmag.com/2018/07/cory-doctorow-zucks-empire-of-o...
Gosh, I hope there will be a #MovingToMattermost movement coming. This feels like a dangerous move to me, and bad for the market, competitiveness, and users. One more thing the tech world does not need right now, is even further increasing its reliance on a single service (and even more so one with a mediocre track record of uptime).
Interesting idea, but personally I like the Dynamic Range (DR) measurement developed by the Pleasurize Music Foundation more. It also provides a one-value output that has a direct relation to the statistics of the input audio, and AFAIK it is a somewhat established measurand in audio engineering.
Self-plug: A while back I reverse-engineered the DR algorithm and implemented it as a Python script. It's [DRmeter on GitHub](https://github.com/janw/drmeter).
From what I quickly gathered from the specs^1, Replay Gain (RG) and Dymanic Range (DR) are indeed similar in the grand scheme of things. Both algorithms employ percentile-based statistic of RMS values. While RG is determined by the 95% percentile of RMS values on 50ms audio frames, DR uses the 80% percentile on 3-second-long audio frame RMS values. So RG is definitely on the side of short-term analysis, while DR is long-term.
What differentiates RG more plainly though is its stronger psycho-acoustical foundation in regards to frequency response: It applies a so-called "Loudness filter" (modelled after the Equal-Loudness contour^2 found in human hearing) before doing the RMS statistics. The Equal-Loudness contour (also known as "Isophone" where I come from) is in turn modelled after non-linear response of the ear to sound pressure levels in relation to the frequency. It basically adjusts for what in layman's terms I'd call "Importance" of the different ranges.
Therefore I'd say RG is very much focused on what human hearing will perceive as loud (too loud, or just loud enough), while DR focuses on "exposing offenders in all ranges of the spectrum". My educated guess would be: Loud bassy sounds would not harm an RG score, while having a significant impact on the DR, as its not attenuating low frequencies.
Would be interesting to see a comparison of the two!
The level of hypocrisy is beyond measure. If "Open Science" was a real thing already, nobody would care about Nature, Elsevier, et al. If there has ever been a danger to open access to scientific research, it's publishing conglomerates that provide little to no value — the exact opposite of what GitHub has been doing the past few years.
Before complaining about others, clean up your own act, Nature.
As per my personal anecdotal evidence: diet is always key to Acne. I have been suffering from Acne vulgaris, Acne conglobata, and—worst of all—Acne inversa for all my life (26yo), and whenever I fell into bad eating habits with lots of (saturated) fats and carbohydrates, my skin issues are worsening. Western food is just poor quality in general, being heavily processed and “enhanced” and all.
I do understand why people would want to speed up their podcasts backlogs—I'm currently about 50% in, working my way through >500 hours of 5by5's Back To Work with Merlin Mann. I've tried speeding that up but one thing in particular causes me to stick with 1.1x at max: it's the connection with the hosts. It's just information (both useful and less so) condensed to be hastily consumed but it discards the dedication the hosts have put into it. Playing off of each other. The inside jokes, the subtle differences in tone and timing.
Maybe I'm just not as good in processing such social interactions at a faster pace than real-time. But I love "sharing a laugh" as if it's happening right now. That feeling completely goes away when the audio is sped up.
> I do understand why people would want to speed up their podcasts backlogs—I'm currently about 50% in, working my way through >500 hours of 5by5's Back To Work with Merlin Mann.
I listen to a lot of podcasts, and if I had a 500-hour backlog in one, I would conclude that I care about other things more, and either unsubscribe and delete it, or stop downloading episodes by default. I used to auto-download Fresh Air, for example, but when it started backing up, I dialed things back, and now listen to 25-50% of episodes. I also used to listen to The Talk Show, but decided there were other things I would rather do.
Humor is a trick to help making information stick in your head. Not a new trick; advertising uses that trick all the time.
There's no way that with speed listening or reading everything sticks equally as listening or reading a 1.0x speed multiplier. It may feel like you got more done, but in reality you did not. You're essentially fooling yourself, feeling like you accomplished more than you did.
I do the same, but with movies/series. I "watch" them on a second screen without being all the time focused to it. Except if its a really good movie/serie. But if it isn't a good one, why watch it in the first place?
Do you have any reason to believe this besides intuition? Anecdotally you'll find lots of people who say they retain a lot more at 2x speed than 1x, including me. Just look around this thread. Here's one study on this I found with a quick search: https://link.springer.com/article/10.1007/s11528-015-0841-2
My own intuition tells me that everyone probably has a maximum (and maybe minimum) speed that they're comfortable with, and there's no reason to assume that a podcast host's preferred speaking rate is the same as an audience member's preferred listening rate.
Speeding up your primary focus is not at all comparable to consuming something as a secondary focus. I agree that "watching" something in the background is terrible for comprehension and retention.
Perhaps I am biased because although my English is quite decent it isn't my native tongue.
I'm not sure if we're discussing the same thing here. I am talking about learning.
Yes, there's also a lot of people who believe speed reading allows them to read quicker. Sure, it might seem that way, but does the information stick? Do you think anecdotal evidence to test if information was learned counts as evidence?
Dr. Barbara Oakley and Dr. Terrence Sejnowski didn't mention your proposed learning method in their Learning How to Learn course [1]. They also debunked speed reading in that course. If your proposed learning method works well, they should incorporate it in their course. However, it seems to go against the principles of chunking and overlearning.
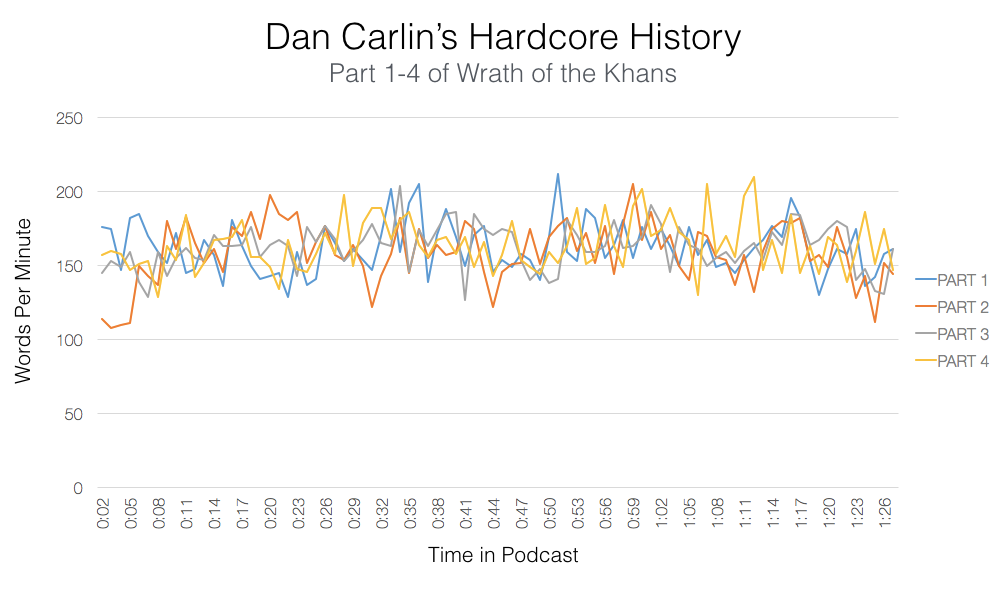
I can't find a definitive source, but the average adult reading speed seems to be around 300 wpm. Popular podcast Hardcore History hovers around ~175 wpm (https://cdn-images-1.medium.com/max/2000/1*_PUpCqAQyCQ-Whf02...), so you'd need to almost double the speed to reach a normal reading pace. So I don't think arguments against speed reading really apply to this.
Of course it all depends on the host. If you find a podcast where the host is already reading at 250 wpm, you'll probably have a hard time catching everything at 2x speed.
Maybe they're catered to the lowest common denominator (the elder).
I've been thinking a bit more about it and I don't remember audio-speedreading being mentioned in the Learning How To Learn course (which I followed, and I hold both teachers in high regard). I think I am biased from the text-speedreading shenanigans.
> Of course it all depends on the host.
Point taken.
My theory is it also depends on the reader. As I grow older, I find it is more difficult to follow things. Sure, my vocabulary still slightly increases but I also think things through more, am more experienced, and eventually I'll end up with Alzheimer's. Hence my suggestion it is catered to the elder. Certainly not for HFAs. (I used to talk very quick as well as child. It was annoying as fuck to everyone, not in the least my parents.)
Reading is not listening though, i'd imagine there's differences in how our brain parses them. This is a very interesting, but exceedingly complex issue.
Nevermind the clever writing but the issue has been known for years—and beautifully exploited with the selfhostable ready-made solution WhatsSpy Public since Feb 2015: https://gitlab.maikel.pro/maikeldus/WhatsSpy-Public/ It's not actively maintained anymore but Maikel deserves some credit for it.
Wanted to post the same. Note that this project used an own client, instead of scraping the webinterface. Which is by far superior, because you don't need an active charged phone and can scale much better. yowsup is still around and working.
Probably not, it used Chat-API [0], but the developer is kind of an asshole. But I admit, people just post stupid issues all the time. However I don't share the developers opinion that this was abused. My friends and I haven't received spam messages on Whatsapp. I admit that may be a small sample size, but still.
I did the same about mid 2015 using yowsup (Python API to Whatsapp). But it's was a private project because of legality concerns of hoarding so much data.
{kind=link}